

Optimizing Maritime Operations Using Reinforcement Learning
Data Science Team, SIYAAugust 6, 2023
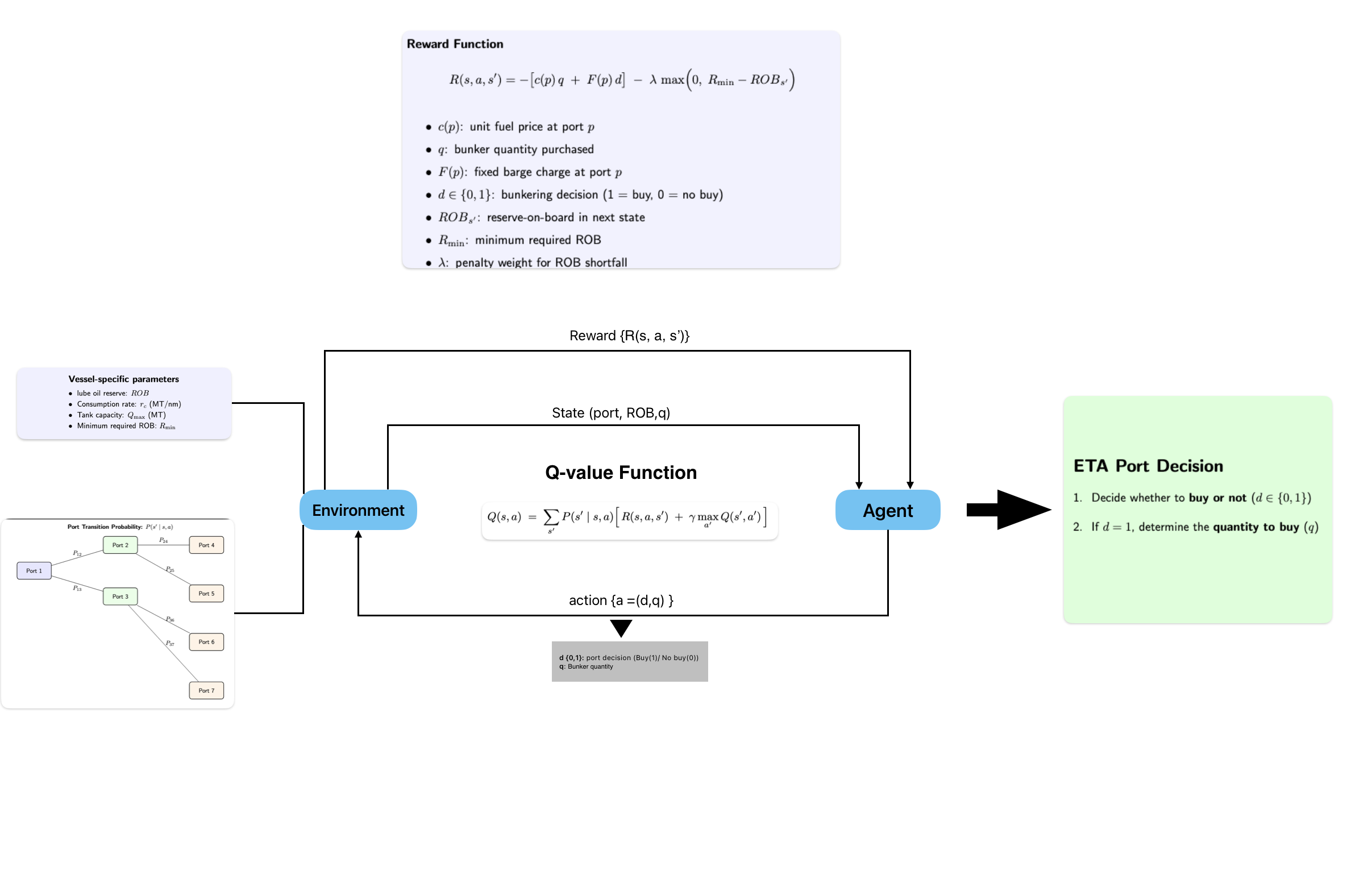
Q-Learning Workflow for Lube Oil Optimization
Abstract
In this paper, we investigate the transformative potential of reinforcement learning (RL) in the maritime industry, with a focus on optimizing operational efficiency and reducing costs. Our team has explored multiple use cases of RL, placing primary emphasis on a cost-efficient lube oil refill strategy for vessels. Utilizing the Q-learning algorithm, we developed a model that optimizes lube oil refills by considering various operational parameters, including consumption rates, port distances, and refilling costs. Our results demonstrate the model’s effectiveness in minimizing operational costs while ensuring sufficient lube oil availability. Additionally, we discuss other promising applications of RL in maritime operations, such as route optimization, fuel management and predictive maintenance. This research showcases the broad applicability and significant benefits of RL in enhancing maritime operational efficiency.1. Introduction
The maritime industry continuously seeks innovative solutions to optimize operations and reduce costs. Reinforcement learning (RL), a subfield of machine learning, offers promising techniques to achieve these goals. This paper provides an overview of RL applications in the maritime industry, highlighting research conducted by our team and presenting a detailed use case utilizing the Q-learning algorithm to optimize the lube oil refill strategy.2. Reinforcement Learning in Maritime Industry
Reinforcement learning has significant potential in various maritime applications. Our team at Synergy Marine Group has explored several key areas:Route Optimization
We have researched RL algorithms to find the most cost-effective and safest shipping routes by considering factors such as fuel consumption, weather conditions, and port congestion. This research aims to enhance route efficiency and reduce travel time.Fuel Management
Optimizing fuel consumption based on vessel speed, load, and sea conditions is another area of our research. RL can learn optimal fuel usage patterns, leading to significant fuel savings and reduced emissions.Predictive Maintenance
Our team is investigating RL for predictive maintenance of ships and port equipment. By analyzing sensor data and historical maintenance records, RL can predict maintenance needs, reducing downtime and maintenance costs.Lube Oil Refill Strategy
The reinforcement learning model frames the problem as a Markov Decision Process (MDP). The model learns to make decisions by interacting with the environment, aiming to minimize the total cost while ensuring the lube oil Remaining On Board (ROB) is sufficient. This paper presents a detailed use case where the Q-learning algorithm is used to optimize the lube oil refill strategy for a vessel.3. Cost-Efficient Lube Oil Refill Strategy for Vessels
3.1 Parameters and Environment Setup
The model considers various parameters and environmental factors, such as:- Average per hour consumption of lube oil by the vessel
- Speed of the vessel
- Tank capacity
- Possible next ports and their probabilities
- Price of lube oil at each port
- Delivery charges and policies at each port
- Distances between possible port pairs
- Minimum required ROB
- Maximum quantity of fuel that can be refilled at a port
3.2 MDP Formulation
States: The state represents the current lube oil ROB and the vessel’s location. Actions: The actions are the possible amounts of lube oil to refill at each port. Rewards: The reward is the negative of the cost incurred for refilling lube oil. This encourages the model to minimize costs. Transition probabilities: The transition probabilities are based on the predicted probabilities of visiting the next port.3.3 Reward Function
Let:- : current port
- : unit price of lube oil at port
- : bunker quantity purchased (MT)
- : fixed barge/delivery charge at port
- : bunkering decision (1 = buy, 0 = no buy)
- : reserve-on-board in the next state
- : minimum required ROB
- : penalty weight
3.4 Q-Learning Algorithm
The Q-learning algorithm is used to train the reinforcement learning model. The Q-value is updated using the following equation: where:- Q(s,a) is the Q-value for state s and action a
- α is the learning rate
- R is the reward received after taking action a in state s
- is the discount factor
- s’ is the next state
- a’ is the action that maximizes the Q-value in the next state
Pseudocode
3.5 Implementation
The Q-learning algorithm is implemented by initializing the Q-table with all zeros. Various hyperparameters were experimented with to reach the optimal algorithm. A range of learning rates α (0.1, 0.3, 0.5) and discount factors γ (0.9, 0.95, 0.99) were used over multiple runs. The number of episodes was set to 10,000, and the convergence threshold was defined as the point where the change in Q-values was less than 1e⁻⁶ for 1,000 consecutive episodes. The process started from a random state, selected an action using the epsilon-greedy policy, took the action, and observed the reward and next state. The Q-value was then updated using the Q-learning update rule. This iterative process continued until the algorithm converged to an optimal strategy.3.6 Usage of the Model
The model can be used to determine the optimal refill strategy given the current port and the remaining onboard (ROB) lube oil. Here’s how it works:- Given the current port and the ROB, the model predicts the optimal ports for lube oil refilling
- It provides the possible ports from where lube oil refill should be done and the quantity of refill required
- The model also outputs the cost of refilling at each recommended port, considering the possible routes, associated costs, probabilities, and distances