Abstract
The SIYA memory framework is engineered to move beyond the limitations of standard stateless AI interactions. By implementing a sophisticated, tiered memory architecture, the system mimics human-like cognitive functions: immediate focus, long-term recall, and the iterative synthesis of experience into permanent knowledge. At its core, SIYA distinguishes between raw interaction data—the literal log of what was said—and synthesized reflection—the distilled intelligence of what was learned. This architecture allows the system to manage massive datasets and complex, multi-agent workflows without becoming overwhelmed by noise or reaching token saturation. Through the interplay of Short-Term Active Focus, Session-Specific Persistence, and Global Reflective Knowledge, SIYA maintains a continuous thread of “consciousness” across weeks of inactivity. It doesn’t just process queries; it builds a persistent, evolving understanding of the project’s technical landscape and the user’s individual requirements, ensuring that every session begins with the accumulated wisdom of all previous interactions.1. The Memory Layers
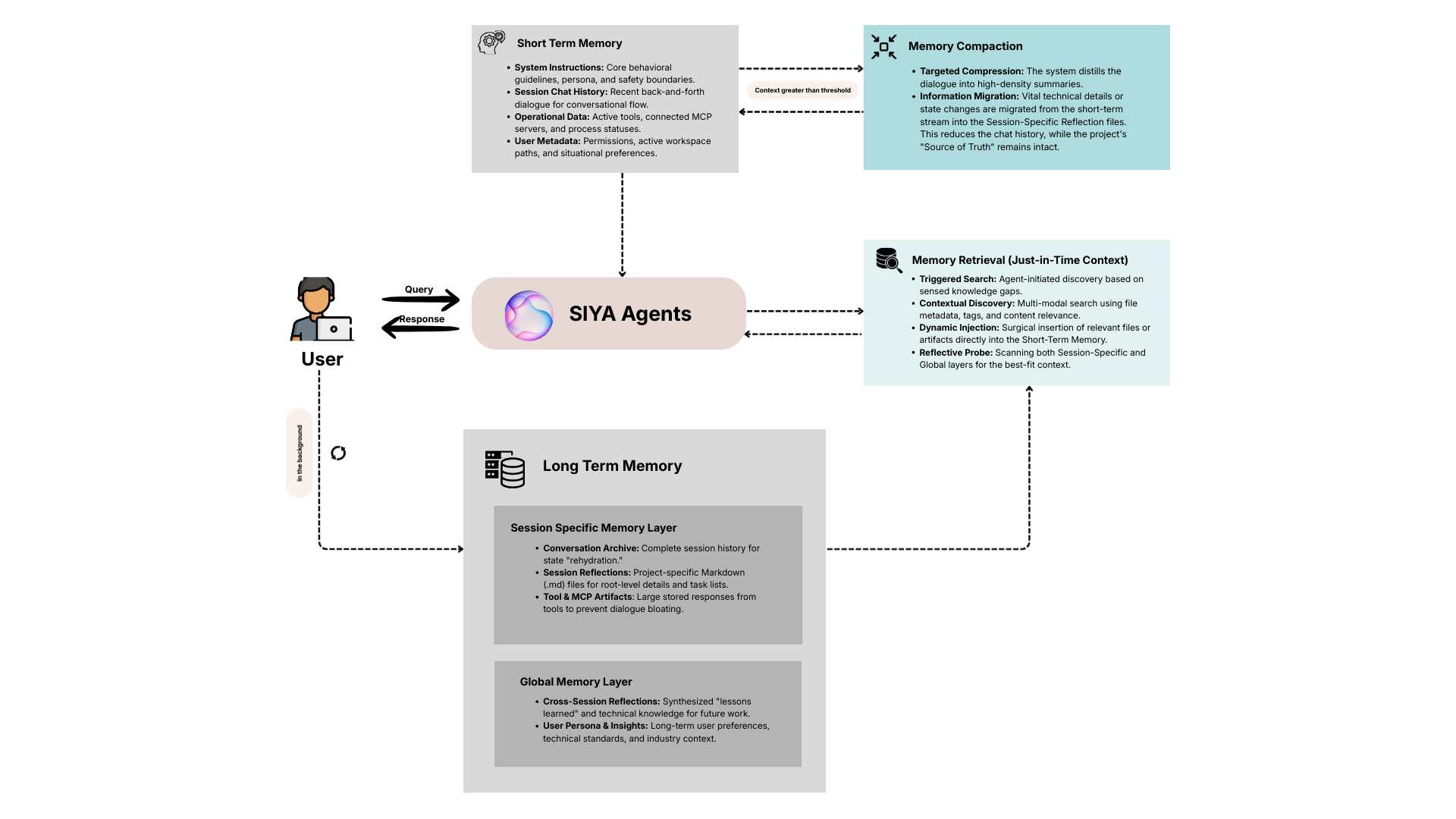
1.1 Short-Term Memory (Active Focus)
This is the immediate “working memory” of the system. It contains the data required for the agent to function in the moment:- System Instructions: The core behavioral guidelines and prompts that define the agent’s persona, capabilities, and safety boundaries.
- Session Chat History: The most recent back-and-forth dialogue between the user and the agent. This allows the system to maintain conversational flow.
- Operational Data: Real-time information regarding active tools, connected MCP servers, and current process statuses.
- User Metadata: Immediate situational data about the user, such as current permissions, active workspace paths, and session-specific preferences.
1.2 Long-Term Memory (Persistent Intelligence)
Long-term memory is partitioned into two distinct scopes to balance project-specific details with global awareness.A. Session-Specific Memory
This scope is tied to a single conversation or a specific project thread. It ensures that the agent remains grounded in the context of the current work:- Conversation Archive: The complete history of the session, allowing the agent to “rehydrate” its state if you return to the chat later.
- Session Reflections: Project-specific Markdown files created by the agent to track root-level details, current task lists, and architectural decisions unique to that session.
- Tool & MCP Artifacts: Large responses from agent tools or MCP servers are stored here as temporary artifacts. This allows the agent to reference massive data outputs without cluttering the active dialogue.
B. Global Memory
This scope persists across all sessions and projects, acting as the agent’s “learned experience”:- Cross-Session Reflections: Knowledge that the agent deems valuable for future work is synthesized into global Markdown files. This allows the agent to carry over “lessons learned” from one project to the next.
- User Persona & Insights: Observations about user preferences, technical standards, and industry context are stored here to provide a personalized experience in every new session.
2. Compaction: Maintaining Performance
To prevent the Short-Term Memory from becoming overwhelmed, SIYA employs a compaction pipeline.- Targeted Compression: When the active conversation reaches a certain limit, the system distills the dialogue into high-density summaries.
- Information Migration: During compaction, any vital technical details or state changes are migrated from the short-term stream into the Session-Specific Reflection files. This ensures that while the chat history is shortened, the project’s “Source of Truth” remains intact.
3. Retrieval: Just-in-Time Context
While the system starts with basic metadata, it relies on a Retrieval Layer to pull deeper knowledge from the Long-Term Memory tiers as needed.- Triggered Search: When the agent determines it needs more information to fulfill a request—or senses it has existing data on a topic—it performs a search across the workspace.
- Contextual Discovery: SIYA uses a combination of file metadata, tags, and content relevance to find the most appropriate Markdown files or tool artifacts from the Long-Term layers.
- Dynamic Injection: Once the relevant information is identified, it is surgically injected into the Short-Term Memory. This ensures the agent is informed by the actual state of your files and global insights without user intervention.
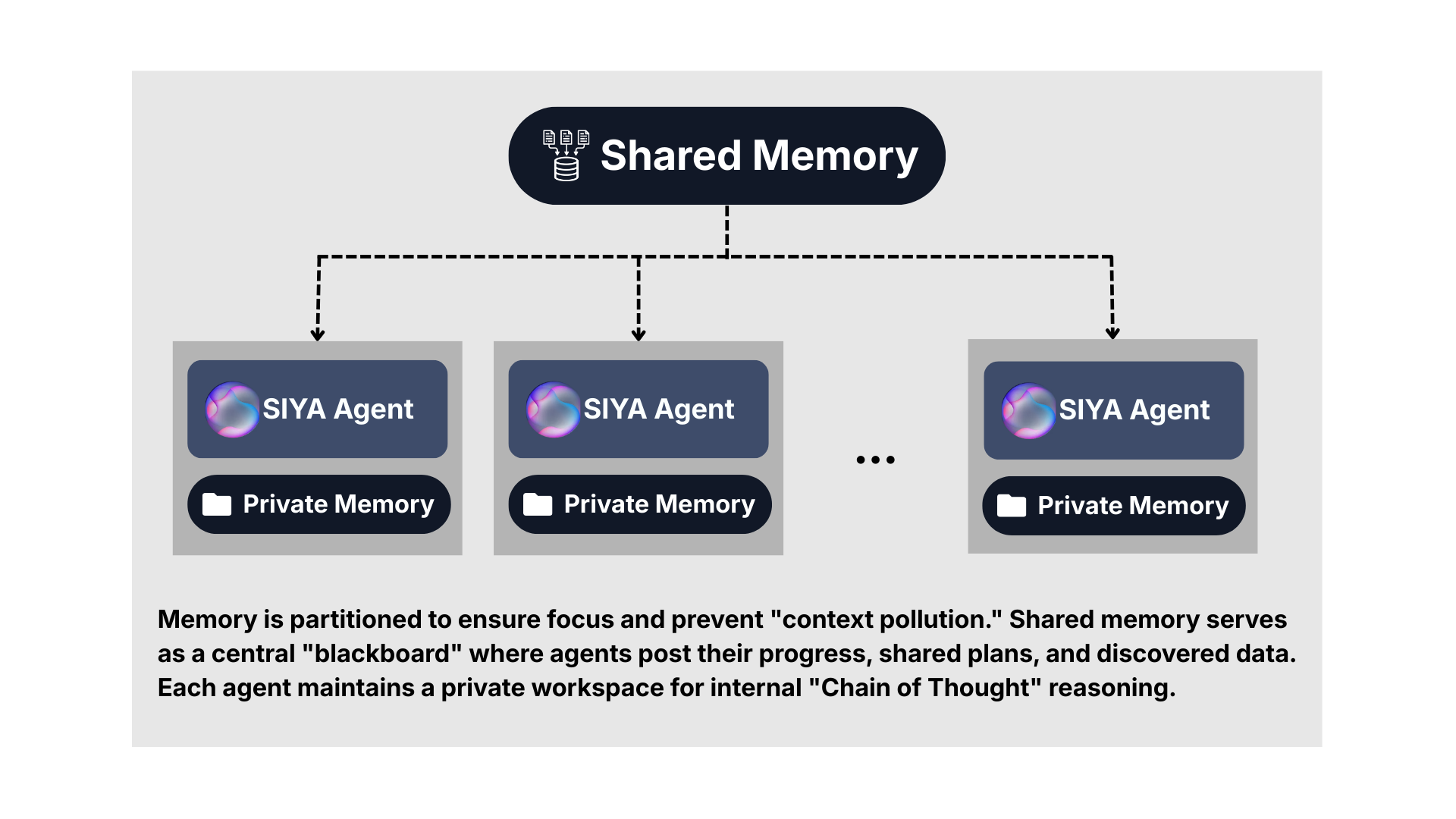
4. Multi-Agent Coordination