

Paradigm Shift in Document Intelligence
You’ve seen the demos and heard the hype. Retrieval-Augmented Generation (RAG) was promised as the key to unlocking the power of Large Language Models (LLMs) with your own private data. The idea is simple: find relevant document snippets and feed them to an LLM for a precise, context-aware answer. However, the reality of enterprise data—with its sprawling compliance documents and complex technical manuals—quickly shatters this promise. To overcome this, we must shift our paradigm from treating documents as unstructured text to understanding them as structured, interconnected sources of knowledge.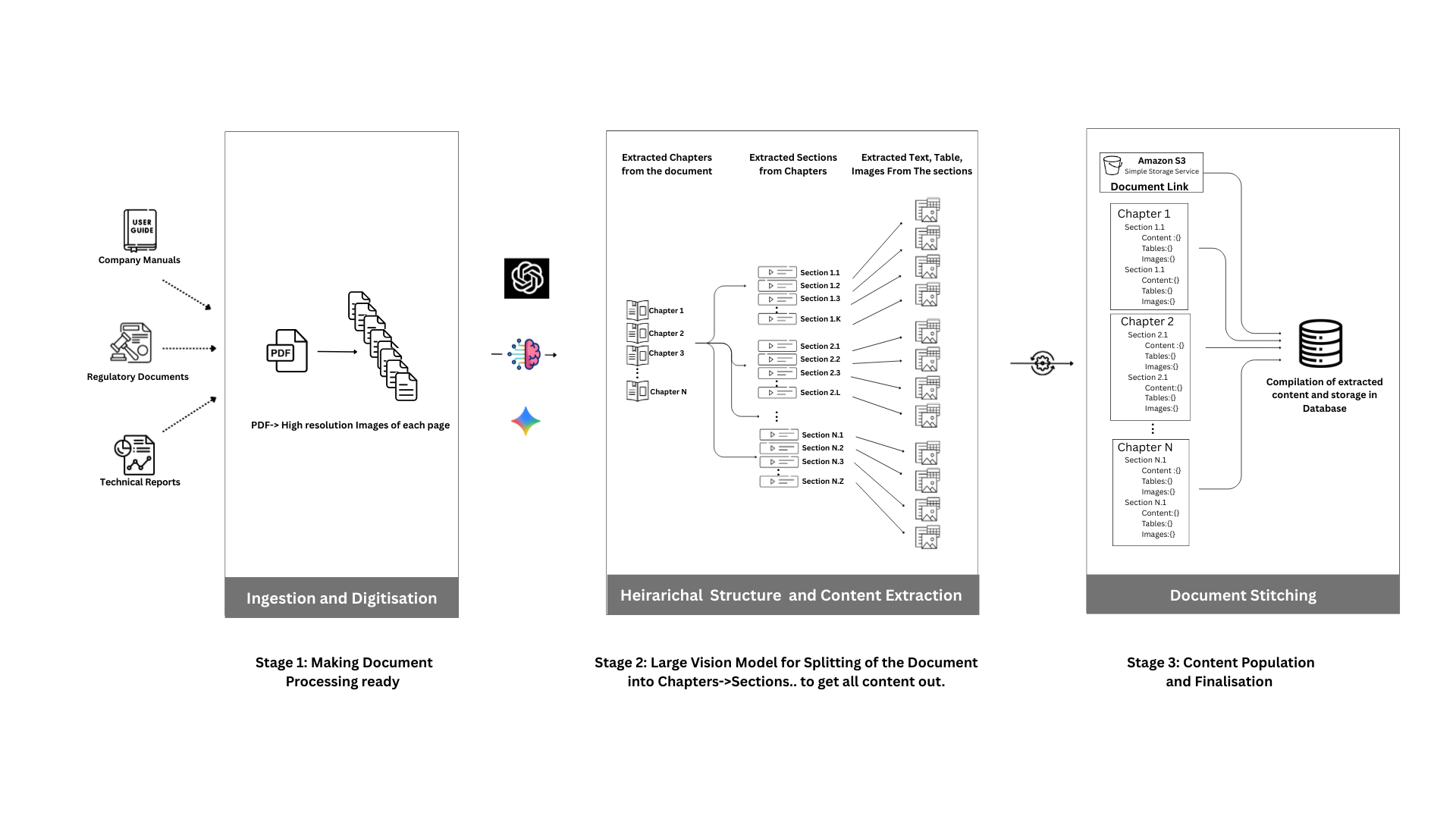
- Deep Ingestion & Structuring: We don’t just index text; we create a detailed, hierarchical map of every document. Our system analyzes a document’s layout, semantic elements, and visual structure to build an intelligent, multi-layered knowledge base where context is preserved.
- Agentic Search & Navigation: We deploy an AI agent that reasons, navigates, and verifies information within this structure. It formulates a plan, traverses the document hierarchy, and validates findings before constructing a fully auditable answer.
The Failure of “Naive” RAG: Why Other Systems Fail
When you move from a curated demo to the messy reality of your enterprise knowledge base, the simple RAG pipeline that worked so well in theory starts to fail, delivering answers that are irrelevant, subtly incorrect, or just plain made up. This is because a “naive” RAG implementation is fundamentally unprepared for the complexity of real-world enterprise data.The Core Problems
Context Blindness: The “Bag of Chunks” Fallacy
Standard RAG pipelines begin by carving documents into arbitrary, fixed-size pieces. A 500-page PDF becomes a collection of hundreds of disconnected “chunks.” This process is like shredding a book and then trying to understand the plot by randomly grabbing a handful of scraps. The model treats your knowledge base as a “bag of chunks,” completely ignorant of the original structure. A chunk from Chapter 5 has no idea it logically follows Chapter 4. This loss of structural context is the root cause of most RAG failures.The “Lost in the Middle” Problem
Research has shown that LLMs often struggle to identify and utilize information located in the middle of a long context window. When a simple vector search retrieves dozens of chunks, the most critical piece of information might be sandwiched between less relevant ones. The LLM’s attention mechanism can fail to pinpoint this “needle in a haystack,” leading it to overlook the very detail that would provide the correct answer.Hallucinations & Imprecision
This is the direct consequence of context blindness. When an LLM is fed a collection of unrelated or semi-related chunks, it does what it’s designed to do: find patterns and generate fluent-sounding text. Without the proper structural guardrails, it stitches these fragments together in ways that seem plausible but are factually incorrect, leading to a confident but dangerously wrong answer.The Black Box: Answers Without Auditability
Perhaps the most significant barrier to enterprise adoption is the lack of transparency. A standard RAG system provides an answer, and maybe a list of source documents, but it rarely shows the exact passages, tables, or figures used to generate the response. For any regulated industry—be it finance, healthcare, or legal—this is a non-starter.How We Are Better: Building a Foundation of Trust
The failures of naive RAG stem from a single, fundamental misunderstanding: treating complex documents as an unstructured soup of text. Our solution is engineered to preserve and leverage a document’s inherent structure from the moment it is ingested.Hierarchical “Smart Chunking”
Instead of blindly splitting text everyN tokens, we perform Hierarchical “Smart Chunking.” Our vision-enhanced parsing first identifies the document’s natural boundaries—chapters, sections, subsections, and even tables. We then chunk along these boundaries, ensuring a single thought is never split across multiple chunks and a heading is never divorced from its content. This creates a coherent and reliable knowledge source where logical context is maintained.
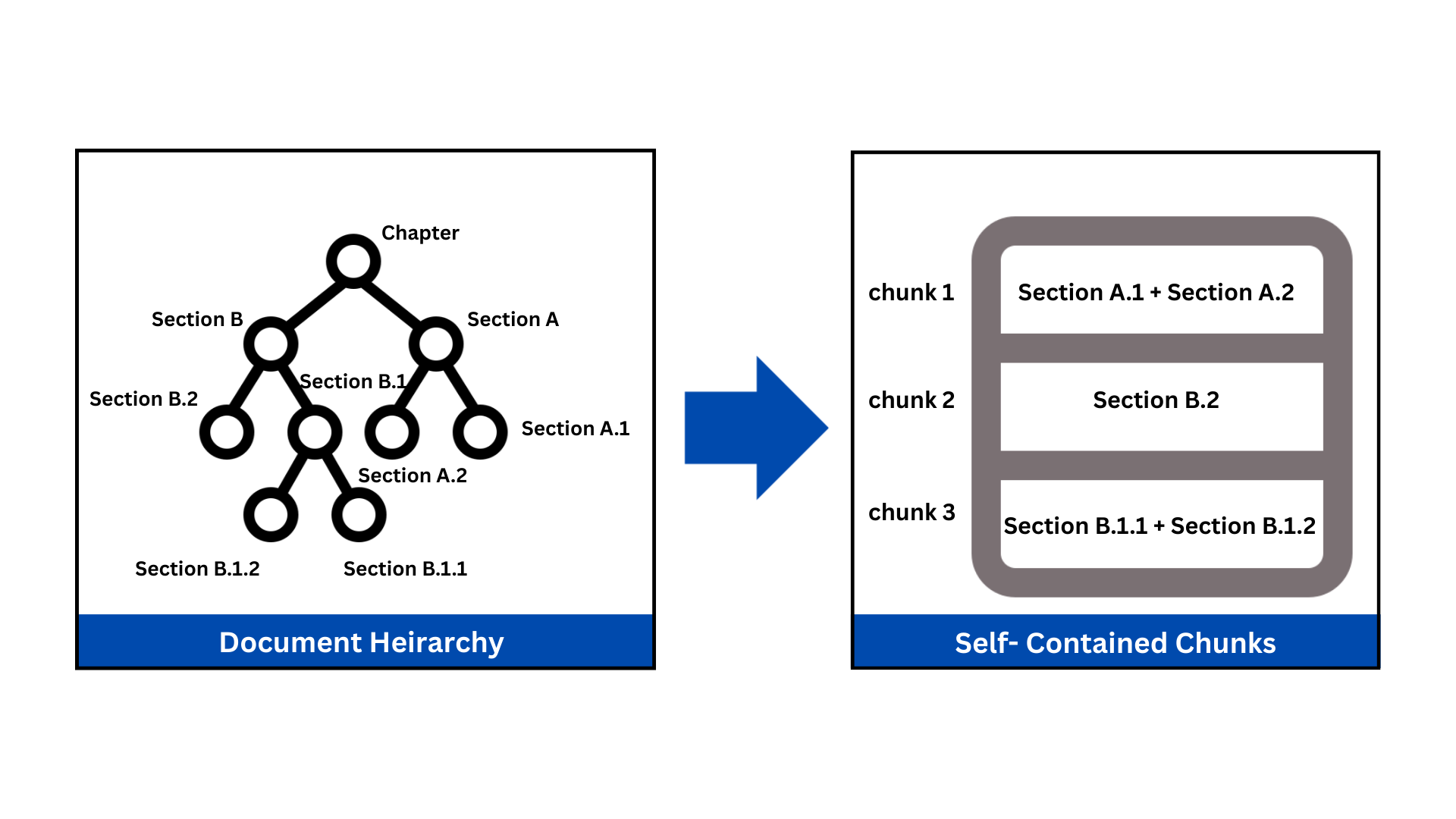
Metadata Enrichment
This is our critical differentiator. A chunk of text without context is useless. Each chunk we create is enriched with a rich payload of metadata, turning it into a precisely located piece of information. This metadata acts as a “GPS” for our retrieval agent, allowing it to navigate the document with pinpoint accuracy.
How It Works: Agentic Navigation and Retrieval
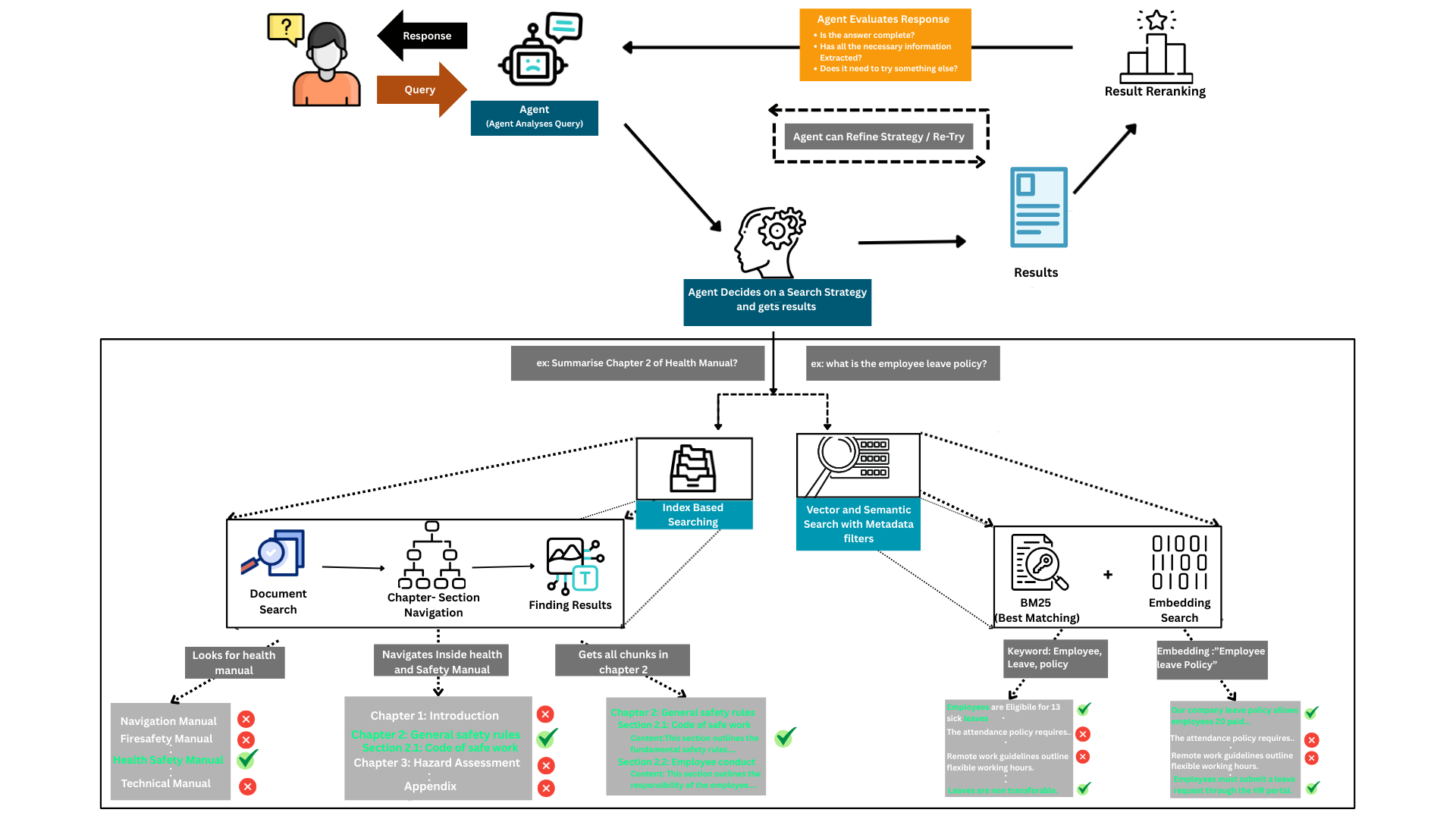
With a well-organized library, our AI agent can now perform retrieval tasks that are simply impossible for standard RAG systems. This is less like a keyword search and more like a conversation with a research assistant. When a user asks a question, the agent first analyzes the query to form a hypothesis and a multi-step search plan. Armed with this plan, the agent uses the rich metadata to navigate the document’s structure, mimicking how a human analyst would conduct research.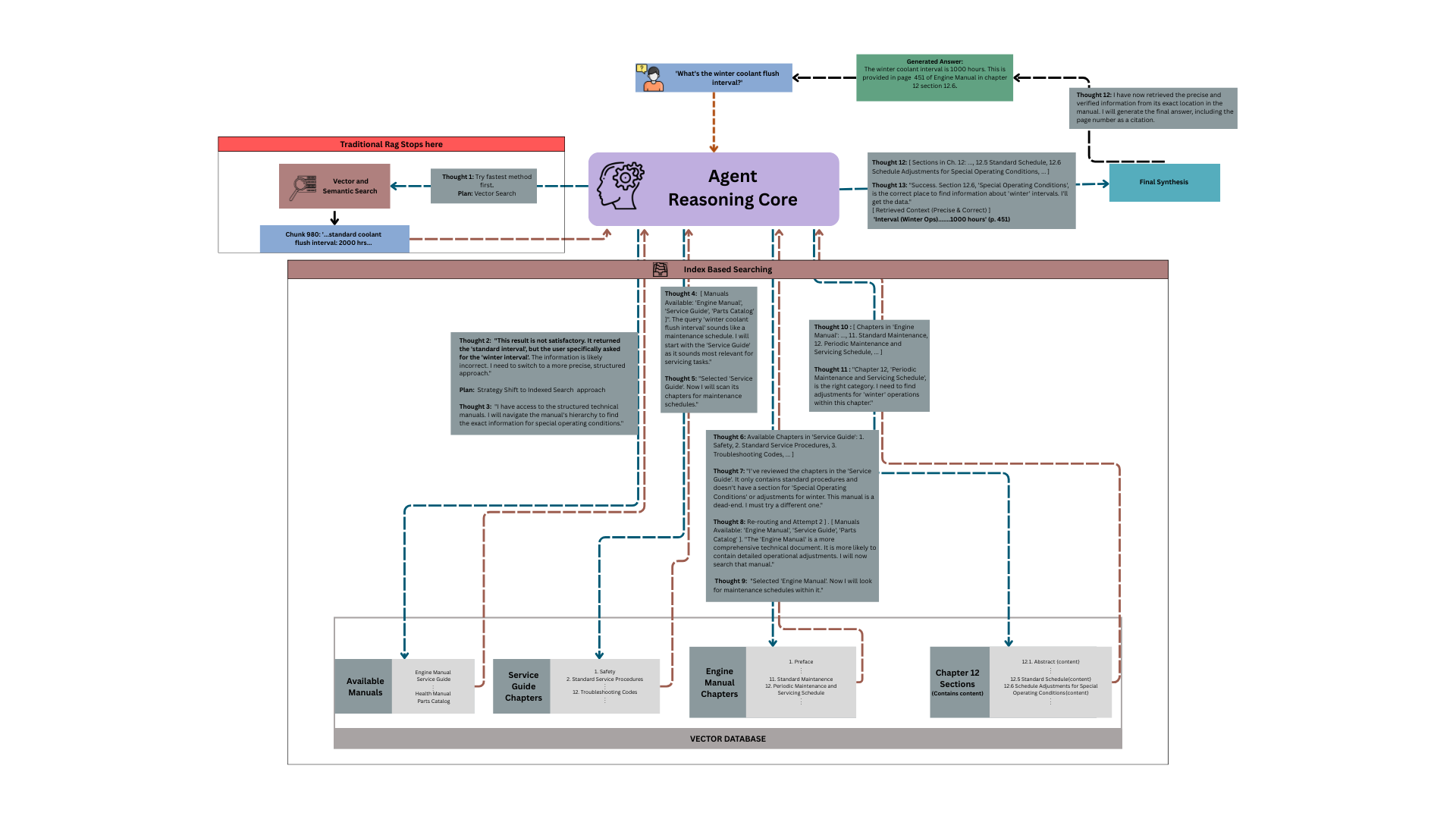
- ”First: I will perform a filtered search for the document where
source_documentisQ3_Financials.pdf." - "Next: Within that document’s metadata, I’ll scan the
hierarchyfor chapter headings containing ‘Financial Performance’." - "Then: Within that chapter, I will perform a vector search for chunks related to ‘profit margins’."
- "Finally: I will analyze the most relevant chunks from that specific section to synthesize an answer.”
Who can use this?
The high success rate of our structuring pipeline on a vast and varied corpus demonstrates the scalability and reliability of our approach. The primary challenge encountered—handling ambiguous sectioning in source documents—highlights the importance of robust guardrails and validation schemas likePydantic in LLM-based workflows. The agent’s ability to navigate a summary tree, rather than searching a flat embedding space, is the key innovation that enables it to reason about document content in a manner analogous to a human analyst. This structured approach circumvents common RAG failure modes like retrieving irrelevant or out-of-context information.
| Aspect | Traditional “Naive” RAG | Our “Agentic” RAG |
|---|---|---|
| Document Handling | Shreds into a “bag of chunks,” destroying structure. | Parses into a hierarchical tree, preserving structure. |
| Retrieval Strategy | Single-shot, flat vector search over all chunks. | Multi-step, recursive navigation of a summary tree. |
| Context Quality | Low. Retrieves a mix of related and unrelated fragments. | High. Pinpoints the single most relevant section. |
| Auditability | None. Cannot provide precise citations. | Excellent. Provides exact page numbers for every answer. |
| Analogy | A keyword search on a pile of shredded paper. | A conversation with an expert librarian using a map of the library. |
Continuous Learning and Feedback Mechanism
To improve system performance over time, a robust feedback loop enhanced with multimodal evaluation is implemented: An evaluator agent assesses the relevance of selected chunks, quality of generated responses, and preservation of multimodal content relationships Human reviewers validate feedback with particular attention to visual element accuracy and structural coherence Validated feedback is incorporated into the agent’s memory experience, including vision-guided chunking quality assessments Continuous refinement of batch processing parameters and hierarchical structure enforcement based on performance metricsThe Enterprise-Grade Solution: Trust at Scale
For an enterprise, RAG is not about querying 10 or 100 documents; it’s about navigating a vast ocean of thousands, or even millions, of interconnected files. In this environment, an answer is worthless without trust. When dealing with regulatory filings, legal contracts, or complex technical manuals, the ability to confirm and audit the source of information is not a feature—it is a fundamental requirement. Naive RAG, with its black-box answers and context-blind retrieval, fails this critical test. Our agentic workflow is designed for this high-stakes reality. By treating documents as structured knowledge and providing a clear, navigable path from question to answer, we deliver a system that is:- Accurate: By understanding context, we avoid the hallucinations and imprecision that plague other systems.
- Auditable: Every answer is backed by precise citations, showing the exact page, section, and table used, ensuring full transparency.
- Scalable: Our structured approach allows the agent to efficiently navigate massive knowledge bases without a drop in performance.